Web缓存技术-Memcached
互联网上的应用、网站,随着用户的增长,功能的增强,会导致服务器超载,响应变慢等问题。缓存技术是减轻服务器压力、加快服务响应时间、提升用户体验的有效途径。Memcached是非常流行的缓存系统,这里介绍对Memcached的安装、设定,以及在集群环境下的使用。
Memcached简介
Memcached是一个开源、高性能、分布式的内存缓存系统,用于加速动态网站的访问,减轻数据库负载。
Memcached使用了Slab Allocator的机制分配、管理内存,解决了内存碎片的问题。
Memcached虽然可以在多线程模式下运行,但线程数通常只需设定为与CPU数量相同,这一点与Nginx的设定类似。
Memcached使用
安装:
在CentOS下使用下面的命令安装:
sudo yum install memcached
启动:
memcached -m 100 -p 11211 -d -t 2 -c 1024 -P /tmp/memcached.pid
-m 指定使用的内存容量,单位MB,默认64MB。
-p 指定监听的TCP端口,默认11211。
-d 以守护进程模式启动。
-t 指定线程数,默认为4。
-c 最大客户端连接数,默认为1024。
-P 保存PID文件。
关闭:
kill `cat /tmp/memcached.pid`
测试:
使用telnet连接memcached服务。
telnet localhost 11211
存储命令格式:
set foo 0 0 4
abcd
STORED
<command name> <key> <flags> <exptime> <bytes>
<data block>
<command name> set, add, replace等
<key> 关键字
<flags> 整形参数,存储客户端对键值的额外信息,如值是压缩的,是字符串,或JSON等
<exptime> 数据的存活时间,单位为秒,0表示永远
<bytes> 存储值的字节数
<data block> 存储的数据内容
读取命令格式:
get foo
VALUE foo 0 4
abcd
END
<command name> <key>
<command name> get, gets。gets比get多返回一个数字,这个数字检查数据有没有发生变化,当key对应的数据改变时,gets多返回的数字也会改变。
<key> 关键字
返回的数据格式:
VALUE <key> <flags> <bytes>
CAS(checked and set):
cas foo 0 0 4 1
cdef
STORED
cas <key> <flags> <exptime> <bytes> <version>
除最后的<version>外,其他参数与set, add等命令相同,<version>的值需要与gets获取的值相同,否则无法更新。
incr, decr可对数字型数据进行原子增减操作。
全局统计信息
stats
STAT pid 10218
STAT time 1432611519
STAT curr_connections 6
STAT total_connections 9
STAT connection_structures 7
STAT reserved_fds 10
STAT cmd_get 5
STAT cmd_set 1
STAT cmd_flush 0
STAT cmd_touch 0
STAT get_hits 3
STAT get_misses 2
STAT delete_misses 0
STAT delete_hits 0
...
END
Memcached集群
Memcached本身不做任何容错处理,对故障节点的处理方式完全取决于客户端。对Memcached的客户端来说,不能使用普通的哈希算法(哈希取模)来寻找目标Server,因为这样在有缓存节点失效时,会导致大面积缓存数据不可用。如下图:
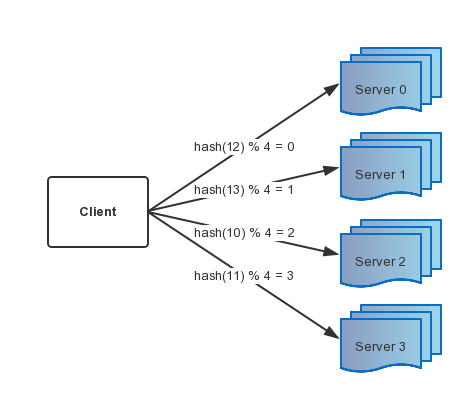

当Server3失效后,客户端需要根据可用Server数量重新计算缓存的目标Server,这时,Key的哈希值为10的数据被指定为由Server1维护,这时原本Server2上可用的缓存也无效了。
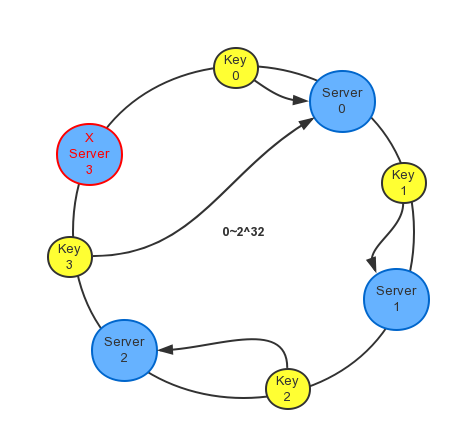
一致性哈希算法
一致性哈希算法解决了在动态变化的缓存环境中,定位目标Server的问题,通常的实现可将它想像成一个闭合的环形。如下图:
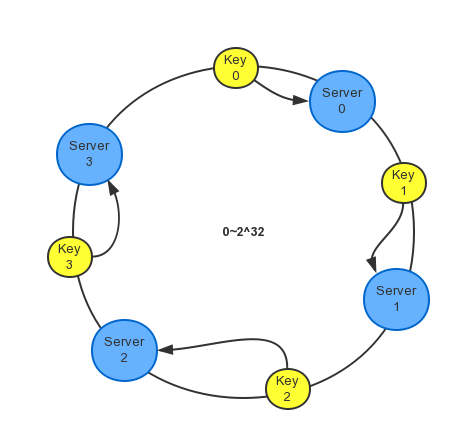
当有节点失效时,不会影响到正常工作的缓存服务器,只有原本分配到失效节点的缓存会被重新分配到下一个节点。如下图: