Node.js的异步I/O
Linux操作系统的I/O模型
JAVA的NIO引入了异步I/O,而Node.js宣称的就是异步编程,I/O自然是异步的。其实操作系统在很早就引入了异步I/O的概念,如下图(摘自Unix网络编程中的图片):
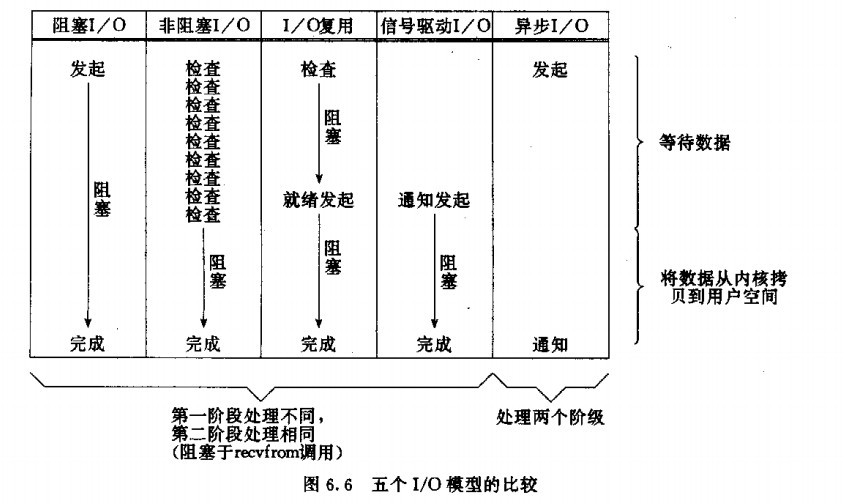
我对上图的理解有几点:
- 从IO设备读取数据到用户内存的整个过程都是由系统内核来完成;
- 数据总是先被拷贝到内核缓冲区,再由内核缓冲区拷贝到用户内存;
- 除了异步I/O,其余4种I/O模型其实都是阻塞的,至少在数据从内核拷贝到用户内存时是阻塞的;
- 虽然异步I/O看上去是理想解决方案,但实现上现在用得最多的应该是多路I/O复用,有select、poll、epoll的实现,性能最好的是epoll;
- 异步I/O现在被认为有缺陷,仅支持O_DIRECT而无法支持系统缓存。
Node.js中的异步I/O
因为内核中的异步I/O有缺陷,现实中的异步I/O通常由用户态的线程池模拟完成,如下图:
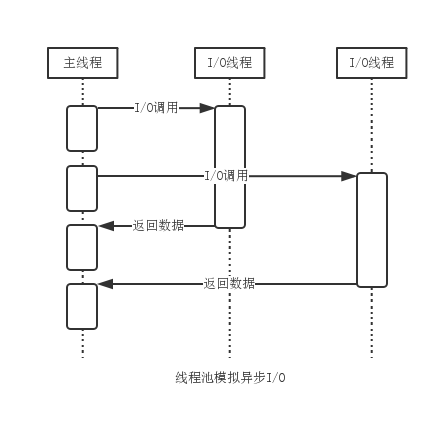
Node.js中原本使用了libeio异步I/O库,在v0.9.3后改为自己实现的线程池来完成异步I/O。所以在Node.js中,除了用户的Javascript代码是单线程外,所有I/O都是多线程并行执行的。
Node.js中的异步I/O调用
Node.js通过事件循环的模式运行,在每一个循环的过程中,通过询问一个或多个观察者来判断是否有事件要处理,而观察者可以有文件I/O观察者、网络I/O观察者等。
Node.js中异步I/O调用的大致流程如下:
- 发起I/O调用
- 用户通过Javascript代码调用Node核心模块,将参数和回调函数传入到核心模块;
- Node核心模块会将传入的参数和回调函数封装成一个请求对象;
- 将这个请求对象推入到I/O线程池等待执行;
- Javascript发起的异步调用结束,Javascript线程继续执行后续操作。
- 执行回调
- I/O操作完成后,会将结果储存到请求对象的result属性上,并发出操作完成的通知;
- 每次事件循环时会检查是否有完成的I/O操作,如果有就将请求对象加入到I/O观察者队列中,之后当做事件处理;
- 处理I/O观察者事件时,会取出之前封装在请求对象中的回调函数,执行这个回调函数,并将result当参数,以完成Javascript回调的目的。